The word mean is often used interchangeably with the word “average.” However, several different things can be called an average; the mean is the most common of those. In this tutorial, "mean” will be used interchangeably with the word “average,” whereas other concepts, such as median, will not be implied.
The mean of a data set is found by adding up all the values together and dividing by how many there are. Notationally, it looks like this:
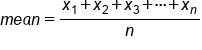
The 1's, 2's, and 3's in the X₁ X₂ X₃--also known as subscripts--indicate the first number in the list, the second number in the list, and so forth, until the last number in the list, marked by the Xn. The “n” value in the denominator is the total number of values.
EXAMPLE
The data set below shows the height of the players on the Chicago Bulls basketball team. What height would be considered average height for basketball players on this team?| Player | Height |
|---|---|
| Omer Asik | 84 |
| Carlos Boozer | 81 |
| Ronnie Brewer | 79 |
| Jimmy Butler | 79 |
| Luol Deng | 81 |
| Taj Gibson | 81 |
| Richard Hamilton | 79 |
| Mike James | 74 |
| Kyle Korver | 79 |
| John Lucas III | 71 |
| Joakim Noah | 83 |
| Derrick Rose | 75 |
| Brian Scalabrine | 81 |
| Marquis Teague | 74 |
| C.J. Watson | 74 |
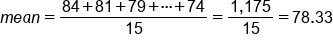

EXAMPLE
Suppose that you have 12 employees. Eight of them are shift workers, three of them are managers, and there’s one boss. Here are the salaries for the respective positions:
| Symbol | Pronunciation | Description |
|---|---|---|
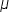
|
"mew" | Is a Greek letter; you will see this quite a lot as a notation for the mean. |
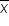
|
“x-bar”: | This is simply an x with a bar over it; you can also use a y-bar, or whatever value you're using. |
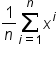
|
"sigma" | Is a Greek letter; called summation notation |
Summation notation, or sigma notation, is a different special notation to shorten up all of this summation. This notation uses the Greek letter, sigma: 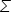 . The compact formula of the summation notation is the same as the lengthier formula.
. The compact formula of the summation notation is the same as the lengthier formula.
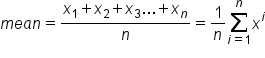
The Xᵢ (read as “x subscript i”) is just like the X₁, X₂, and X₃ in the original summation (from the first section). Therefore, this notation means that the value of Xᵢ will be the sum of all the X's, starting from the first one (where the i value is 1) and finishing at the “nth,” or last, one. When that is completed, you divide by n.
A median is simply a measure of center for the data set that actually finds the middle value in a sorted list. It's the middle number when the data set is arranged from least to greatest or greatest to least.
Recall the list heights of players from the Chicago Bulls basketball team.
| Player | Height |
|---|---|
| Omer Asik | 84 |
| Carlos Boozer | 81 |
| Ronnie Brewer | 79 |
| Jimmy Butler | 79 |
| Luol Deng | 81 |
| Taj Gibson | 81 |
| Richard Hamilton | 79 |
| Mike James | 74 |
| Kyle Korver | 79 |
| John Lucas III | 71 |
| Joakim Noah | 83 |
| Derrick Rose | 75 |
| Brian Scalabrine | 81 |
| Marquis Teague | 74 |
| C.J. Watson | 74 |
You might notice that many of the players are 81 inches tall. Can you, therefore, call that height typical of the Chicago Bulls? To answer that question, you'll need to calculate the median.
In the above list, the players were sorted alphabetically. To find the median, you need to have that list ordered from least to greatest. The first step, therefore, is to reorder those numbers, which will look like this:
71, 74, 74, 74, 75, 79, 79, 79, 79, 81, 81, 81, 81, 83, 84
To find the middle number, start by crossing off the lowest and highest numbers and continue working your way in until you have just one number left.
71, 74, 74, 74, 75, 79, 79, 79, 79, 81, 81, 81, 81, 83, 84,
In this case, the remaining number is 79, which is the median. Notice that half the values in the list are at or below 79, and half the values in the list are at or above 79.
You can also use technology to figure out the median of a data set. Place the list of heights, not ordered, in a spreadsheet. Type "= median(". Then, select the full range of numbers for which you want to find the median, close the parentheses, and hit "Enter".

Using this method, your spreadsheet will give you a median of 79, just like the first method above.
If you have an even set of data, such as 16 pets or 20 courses, finding the median will take an extra step.
EXAMPLE
Suppose you have a class of 10 students and you have a 10-point quiz. Below are the scores from each of the students. What is the median?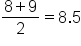
Obviously, one of these values, 90, is completely out of range, perhaps because of a typo. Despite this typo, however, the median of this data set is 7 because that is the middle number. If you correct the typo, changing that 90 to a 9, for instance, the median will still be 7.
2c. Median Class
Another way to figure out a median is to use data summarized in a frequency table, which can help you find the median class.
When is it best to use a frequency table? Let's explore an example. Here is information about the number of days that the temperature was in a particular range in Chanhassen, Minnesota in 2009:
| Temperature | Frequency | Cumulative Frequency | Relative Cumulative Frequency |
|---|---|---|---|
| -10 - -1 | 3 | 3 | 0.01 |
| 0 - 9 | 8 | 11 | 0.03 |
| 10 - 19 | 25 | 36 | 0.10 |
| 20 - 29 | 39 | 75 | 0.21 |
| 30 - 39 | 30 | 105 | 0.29 |
| 40 - 49 | 51 | 156 | 0.43 |
| 50 - 59 | 46 | 202 | 0.55 |
| 60 - 69 | 39 | 241 | 0.66 |
| 70 - 79 | 80 | 321 | 0.88 |
| 80 - 89 | 40 | 361 | 0.99 |
| 90 - 99 | 4 | 365 | 1.00 |
You can see, for example, that eight days had a temperature of between 0 and 9 degrees Fahrenheit. Using this table, there are a couple of different ways to find not exactly what the median temperature is, but which bin it's in.
| Temperature | Frequency | Cumulative Frequency | Relative Cumulative Frequency |
|---|---|---|---|
| -10 - -1 | 3 | 3 | 0.01 |
| 0 - 9 | 8 | 11 | 0.03 |
| 10 - 19 | 25 | 36 | 0.10 |
| 20 - 29 | 39 | 75 | 0.21 |
| 30 - 39 | 30 | 105 | 0.29 |
| 40 - 49 | 51 | 156 | 0.43 |
| 50 - 59 | 46 | 202 | 0.55 |
| 60 - 69 | 39 | 241 | 0.66 |
| 70 - 79 | 80 | 321 | 0.88 |
| 80 - 89 | 40 | 361 | 0.99 |
| 90 - 99 | 4 | 365 | 1.00 |
You can see that the 183rd day of the year falls in the 50-59 category. That means that 182 days were as cold or colder than that particular day, and 182 days were at least as warm as that particular day, which means that these are semi-ordered by temperature. Thus, the median is somewhere in the 50's.
You can't be 100% sure exactly where in the 50's it is, but you can be sure that it's in the 50's. Notice the number 183, when you look at the cumulative frequency, falls between the 156 and the 202. By the time you've gotten to the end of the temperatures in the 40's, you haven’t accounted for half the days in terms of ordered temperatures. But by the time you finish the 50's, you have accounted for more than half the days, which means that the median is somewhere in the 50's.
If you look at the relative cumulative frequency column, you can see the same thing. By the time you have finished the 40's, you've accounted for less than 43% of the data. By the time you finish the 50's, however, you will have accounted for over 55% of the data.
Where's the 50th percentile? You don't know what the number is, but again, you know it's somewhere in the 50's: 50% of days fall in or below the 50's. Therefore, you would call the 50's the median class because you know the median is somewhere in that bin.
There are a couple of different ways to go about determining what would be considered typical for a set of data:
In a quantitative set, the mode is the most frequently occurring number or numbers, assuming that they occur more than once.
EXAMPLE
Recall our list from above detailing the heights of the Chicago Bulls basketball team. Using this list, can you find out what height would be considered the mode?| Player | Height |
|---|---|
| Omer Asik | 84 |
| Carlos Boozer | 81 |
| Ronnie Brewer | 79 |
| Jimmy Butler | 79 |
| Luol Deng | 81 |
| Taj Gibson | 81 |
| Richard Hamilton | 79 |
| Mike James | 74 |
| Kyle Korver | 79 |
| John Lucas III | 71 |
| Joakim Noah | 83 |
| Derrick Rose | 75 |
| Brian Scalabrine | 81 |
| Marquis Teague | 74 |
| C.J. Watson | 74 |
You can also find the mode of a qualitative data set. In a qualitative data set, the mode is the most frequently occurring category or the largest category.

In the pie chart above, there are several large categories, but the largest category is the red one: biology. Therefore, biology would be the mode of this data set.
3b. Distributions
In a distribution that is fully graphed out, you might have something that's multi-peaked, like in the graph below.

As this graph shows, there is a gap between the two highest peaks, where the amounts decrease very precipitously and then rise again. In a distribution, we would call both of these areas modes. The values near five and eight would both be considered modes because they are the different peaks in the distribution. It might still be called bimodal, although in reality there is only the one mode, the highest bar at eight.
Source: Adapted from Sophia tutorial by Jonathan Osters.
