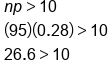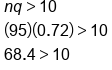This tutorial will cover the normal distribution approximation of the binomial distribution. Our discussion breaks down as follows:
1. Binomial Distribution
First, let's review the binomial distribution itself:

Using that formula, you can create a probability distribution for all the values of k: zero successes, one success, two successes, all the way up to n successes.
That can be made into a histogram, where the x-axis represents the values of k, the number of successes; and the y-axis is the relative frequency of those successes. Each bucket for the values of k go up to the height corresponding to the probability.
Just like all distributions, the binomial distribution has a mean and a standard deviation. The mean is fairly obvious to calculate.
-
EXAMPLE
Consider the scenario where you roll a die six times. The question is, how many times would you anticipate rolling a two? What if the number of rolls increased to 60 or even 600? How would your expectations change?
- The probability of rolling a two on a six-sided die is 1/6. This means that for every six rolls, you can expect one of them to result in a two. So, if you roll the die six times, you expect, on average, to roll a two once. This is because 1/6×6=1
- If you increase the number of rolls to 60, you would expect to roll a three about 10 times. This is calculated as 1/6×60=10.
- Similarly, if you roll the die 600 times, you would expect to roll a three about 100 times, since 1/6×600=100
-
The average, or the expected value, is going to be the number of trials times the probability of success.
For a binomial distribution, we can identify the mean, standard deviation, and variance:
-
- Mean of a Binomial Distribution
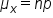
- Standard Deviation of a Binomial Distribution
-
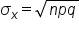
- Variance of a Binomial Distribution
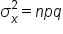
2. Normal Distribution Approximation of the Binomial Distribution
Every distribution has three key features:
- Center
- Spread
- Shape
You just dealt with center and spread by finding the mean and the standard deviation.
-
- Center of a Binomial Distribution
- Spread of a Binomial Distribution
But what about the shape? Shape of this distribution is affected by two things: both n and p.
Look at the following distributions for a high, low, and middle probability. Notice how the distribution changes as the probability changes and number of trials change.
High Probability
p = 0.90
|
|---|
|
Number of Trials
|
Distribution
|
|
10
|

|
|
100
|

|
When the probability of success is very high, the distribution is skewed very heavily to the left when the number of trials is low. But as the number of trials increases, the distribution is nearly symmetric. It's a little skewed to the left, but not heavily skewed as with the lower number of trials.
Low Probability
p = 0.15
|
|---|
|
Number of Trials
|
Distribution
|
|
10
|

|
|
100
|

|
When the probability of success is very low, the distribution is skewed very heavily to the right when the number of trials is low. But as the number of trials increases, the distribution is now only slightly skewed to the right.
Moderate Probability
p = 0.50
|
|---|
|
Number of Trials
|
Distribution
|
|
10
|

|
|
100
|

|
When the probability of success is moderate, near 0.50, the distribution becomes nearly symmetric when the number of trials is low. As the number of trials increases, the distribution stays symmetric.
That's what you should see when we look at the normal distribution approximation of the binomial distribution.
-
When n is high, the distribution is approximately normal. The only exceptions are when the value of p is very low or very high. When n is low, the skew, if any, is more prominent.
This is a critical concept. This means that when you have a large number of trials, the distribution of binomial probabilities is nearly normal, with the mean of what you found the mean to be, and standard deviation of what you found the standard deviation to be. Ultimately what you're finding is the binomial distribution with parameters n and p--which is what makes the binomial look like what it looks like--looks a lot like the normal distribution with that mean and that standard deviation.
The distribution has to be large enough to satisfy these two conditions:
- The mean, np, has to be at least 10.
- The expected number of failures, nq, has to be at least 10.
This means that you had to be far enough off of the left-hand side and far enough off the right-hand side. When you had that distribution, it looked normal when you were safely in the middle of the distribution, and not near the very ends. These two conditions have to be satisfied. This makes looking at a lot of these problems much easier.
-
EXAMPLE
Suppose a baseball player gets a hit 28% of the time when he comes to bat. What’s the probability that he gets over 30 hits in his next 95 at bats?
Using the old way, you would have to find the probability that he gets exactly 31 hits, plus the probability that he gets exactly 32, all the way up to the probability that he gets exactly 95 hits. But if you completed all 65 calculations, you would get a probability of 0.18546, or 18.5%.

The new way uses the normal approximation. First, check to see if the distribution is large enough to satisfy the two conditions above. We know there are 95 trials, the probability of success is 0.28, and the probability of failure is 1 minus 0.28, or 0.72.
Both conditions are satisfied, np and nq are both bigger than 10. We can now find the mean and standard deviation.

Using the mean of 26.6 and a standard deviation of 4.376, the normal distribution, or the binomial distribution, is going to look like the image below. The shaded area represented the probability of hitting over 30 hits.

-
Notice that we are using "30.5" in this instance instead of "30.0". This is because we are using the normal distribution, which is continuous, to approximate a discrete distribution, in which partial hits are not allowed. By using a half value, we more closely approximate the probability area associated with the discrete distribution. The term for this is continuity correction and it is not something you are required to do this in this course.
Based on this normal distribution, calculate out a z-score and use a z-table to find the probability that way.

This is almost the same as what you would get if you used the binomial calculations.
-
- Normal Distribution Approximation of the Binomial Distribution
- If a random variable has a binomial distribution, the number of trials is sufficiently large, and the probability of success is not too close to 0 or 1, the variable's distribution can be approximately modeled using a normal distribution.
The normal distribution is a good approximation for the binomial under certain conditions: n has to be large, and p has to be not too extreme, meaning not too high and not too low. You can use the mean and standard deviation of the binomial as the mean and standard deviation for the normal, and use z-scores to find the probabilities. This simplifies the problem.
Good luck!