Table of Contents |
In a z-test for means, the z-test statistic is equal to the sample mean minus the hypothesized population mean, over the standard deviation of the population divided by the square root of sample size.
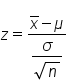
However, the z-statistic was based on the fact that the population standard deviation was known. If the population standard deviation is not known, we need a new statistic. We're going to use our sample standard deviation, s, instead.
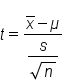
The only problem with using the sample standard deviation (s) as opposed to the population standard deviation (σ) is that the value of s can vary largely from sample to sample. Sigma (σ) is fixed, so we can base our normal distribution off of it.
The sample standard deviation is more variable than the population standard deviation and much more variable for small samples than for large samples. For large samples, s and sigma are very close, but with small samples particularly, the value of s can vary wildly.
Because s is so variable, it creates a new distribution of test statistics much like the normal distribution, but is known as the student's t-distribution, or sometimes just the t-distribution.

The only difference is the t-distribution is a more heavy-tailed distribution. If we used the normal distribution, it would underestimate the proportion of extreme values in the sampling distribution.
The t-distribution is actually a family of distributions. They all are a little bit shorter than the standard normal distribution and a little heavier on the tails. As the sample size gets larger, the t-distribution does get close to the normal distribution. It doesn't diminish as quickly in the tails when the sample size is small, but gets very close to the normal distribution when n is large (>30).
Source: THIS TUTORIAL WAS AUTHORED BY JONATHAN OSTERS FOR SOPHIA LEARNING. PLEASE SEE OUR TERMS OF USE.
