Table of Contents |
A test statistic is a measure that quantifies the difference between the observed data and what is expected under the null hypothesis. It is expressed in terms of how many standard deviations an observed mean or proportion is what would be expected by the null hypothesis.
When we have a hypothesized value for the parameter from the null hypothesis, we might get a statistic that's different than that number. So, it's how far it is from that parameter.
The basic test statistic formula is equal to the statistic minus the parameter, divided by the standard deviation of the statistic.

When dealing with means, we can use the following values:
| Z-Statistic for Means | |
|---|---|
| Statistic |
Sample Mean: 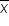
|
| Parameter |
Hypothesized Population Mean: 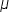
|
| Standard Deviation |
Standard Deviation of : 
|
Therefore, the z-statistic for sample means that you can calculate is your test statistic, and it is equal to x-bar minus mu (μ), divided by the standard deviation of x-bar. Now we will start formalizing its use and be able to tackle those edge case scenarios where the means are moderately far apart.
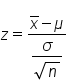
Meanwhile, for proportions, we can use the following values:
| Z-Statistic for Proportions | |
|---|---|
| Statistic |
Sample Proportion: 
|
| Parameter |
Hypothesized Population Proportion: 
|
| Standard Deviation |
Standard Deviation of : 
|
Therefore, the z-statistic for sample proportions that you can calculate is your test statistic, and it is equal to p-hat minus p from the null hypothesis, divided by the standard deviation of p-hat.

Both these situations have conditions under which they're normally distributed. You can use the normal distribution to analyze and make a decision about the null hypothesis.
The normal curve below operates under the assumption that the null hypothesis is, in fact, true.

Suppose you are dealing with means. In the following graph, the parameter mean is indicated by mu (μ), the standard deviation of the sampling distribution is sigma over the square root of n, and perhaps your statistic x-bar is over to the right as indicated below. The test statistic will become a z-score of means.

You are going to find what is called a p-value, the probability that you would get an x-bar at least as high as what you'd get if the mean really is over here at the mean, mu (μ). In this particular case, it's one sided-test.
We could do that, or if it were a two-sided test, it would look like this:

A common and related way to determine statistical significance is to compare your z-score to what's called a critical value. This corresponds to the number of standard deviations away from the mean that you're willing to attribute to chance.
EXAMPLE
You might say that anything within this green area here is a typical value for x-bar.

With two-tailed tests like the image above, the critical values are actually symmetric around the mean. That means that if you use positive 2 (1.96) on the right side, you would be using negative 2 (-1.96) on the left side.
There are some very common critical values that we use. The most common cutoff points are at 5%, 1%, and 10%, and you can see their corresponding critical values, which is the number of standard deviations away from the mean that you're willing to attribute to chance.
| Tail Area |
|
|
|---|---|---|
| Two-Tailed | One-Tailed | Critical Value (z*) |
| 0.05 | 0.025 | 1.960 |
| 0.10 | 0.05 | 1.645 |
| 0.20 | 0.10 | 1.282 |
| 0.01 | 0.005 | 2.576 |
| 0.02 | 0.01 | 2.326 |
For a two-tailed with 0.05 as your significance level, you will consider a result to be significant if the z-score is at least 1.96 standard deviations from the expected value.
If you were doing a one-tailed test with 0.05 as your significance level or a two-tailed test with rejecting the null hypothesis if it's among the most 10% extreme values, you'd use a z-statistic critical value of 1.645.
If you were doing a one-tailed test and you wanted to reject the most extreme 10% of values on one side, you'd use 1.282 for your critical value.
When you run a hypothesis test with the critical value, you should state it as a decision rule. For instance, you would say something like, "I will reject the null hypothesis if the test statistic, z, is greater than 2.33". That's the same as saying that on a right-tailed test, reject the null hypothesis if the sample mean is among the highest 1% of all sample means that would occur by chance. Note this is one-tailed because you're saying that the rejection region is on the high side of the normal curve.
Consider the curve below:

Source: THIS TUTORIAL WAS AUTHORED BY JONATHAN OSTERS FOR SOPHIA LEARNING. PLEASE SEE OUR TERMS OF USE.


